SQL Join Algorithm
- Notations:
- $[T]$: Number of pages in table T
- $\rho_T$: The number of records on each page of T
- $|T|$: The total number of records in table T, $|T| = [T] \times \rho_T$
# Nested Loop Join
# Simple Nested Loop Join
- IO Count: $[R] + |R|[S]$
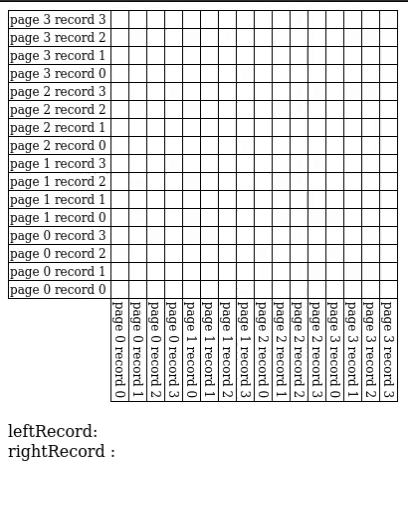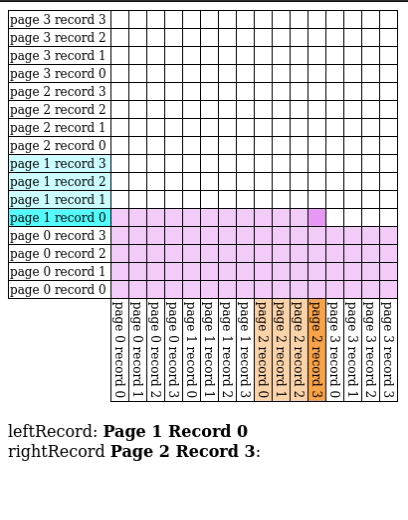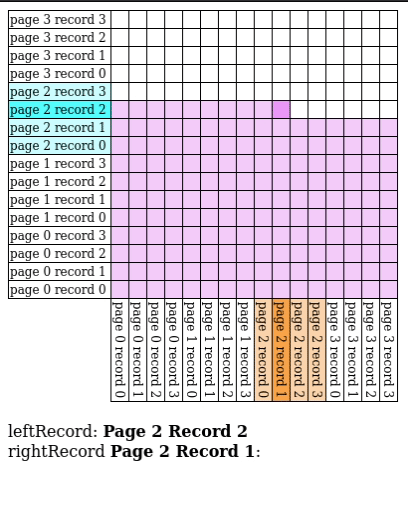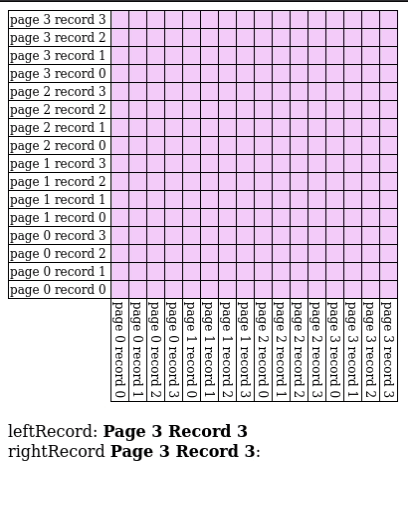
# Page Nested Loop Join
- IO Count: $[R] + [R][S]$
- $S$ should be the smaller table to minimize the IO cost.
- Read in every single page in $S$ for every single page of $R$
- A special case of block nested loop join with $B = 3$

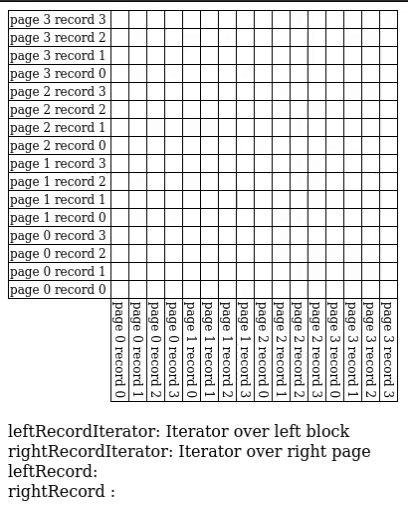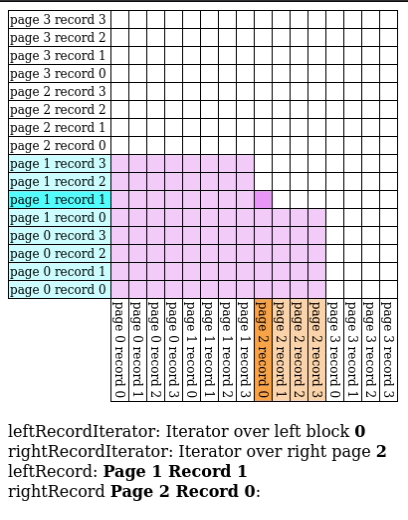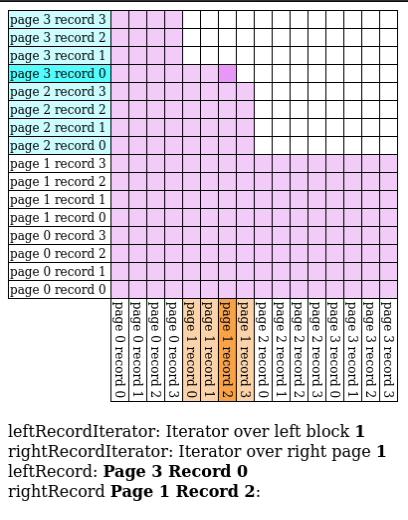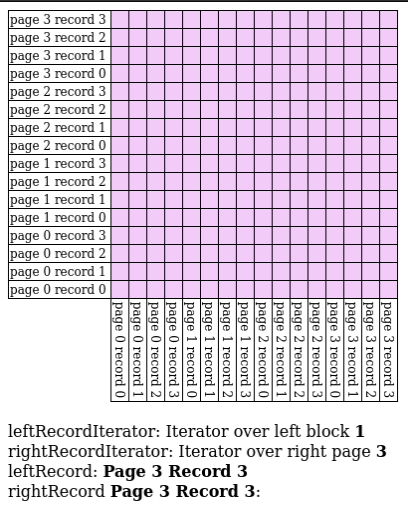
# Block Nested Loop Join
We have $B$ buffer pages to spare, give $B-2$ pages to $R$ and match $S$ against every record in the buffer.
- IO Count: $[R] + \frac{[R]}{B-2}[S]$
# Hash Join
- Key Skew: many of the records have the same key. Cause some bucket much larger than others, leading to performance issues in join algorithms that rely on hash tables.
# Grace Hash Join
- Idea: partitioning the input relations into smaller subsets, hashing each subset, and then joining the hashed partitions.
- Procedures: Repeatedly hash $R$ and $S$ into $B-1$ buffers so that we can get partitions that are $\leq B - 2$ pages big.
- Notes: sensitive to key skew.
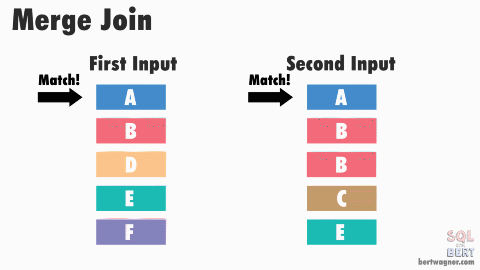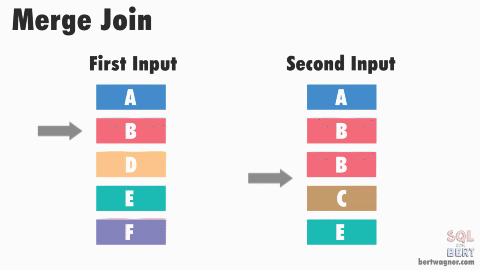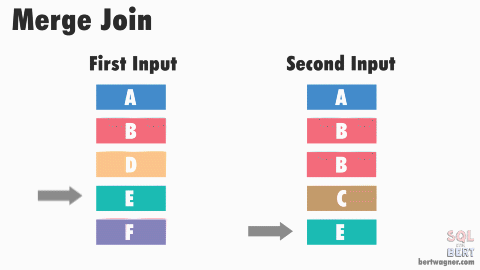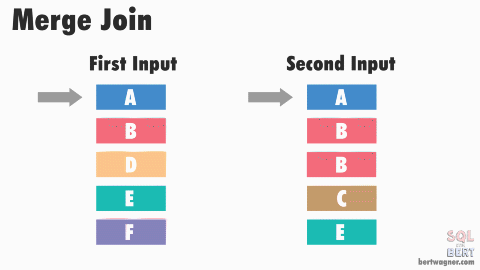
# Sort Merge Join
- IO Count: Cost to sort $R$ and $S$ $+ ([R] + [S])$
- External Sort
- If first input is smaller than second input, advance
- advance second input till end
- advance first input till end